Text Classification with Spacy 3.0
Build a news headline classifier on the command line

From intent classification in virtual assistants like Alexa & Google Home, through to sentiment analysis and topic identification — text classification can power many different applications.
Text classification is the job of predicting which category a piece of text belongs to. If for example the categories are intents for and the inputs are short instructions like ‘play music’ or ‘tell me the weather’, then text classification can form the basis of a virtual assistant. If, instead, the categories are sentiment — positive, negative & neutral — and the inputs are tweets, then the text classification can form the basis of Twitter sentiment detection. With careful choice of categories and data, text classification can be applied to a multitude of applications.
This post prototypes a text classifier using Spacy’s command line tools. All you need to get started is a working Python installation, with Spacy installed.
Step 1 — Data Preparation
The first step is to decide what task to work on. That means identifying a) the data to work on, and b) the names of categories the data can be classified into. On your own data, you can use a tool like Prodigy or Label Studio to manually label with your own categories. In this post though, we’re going to use an already-labelled dataset that’s freely available on Kaggle. The set is labelled for a news headline classification task. Downloading the data and taking a look, we can see that it’s a single file where each line of the data is a small json object:
{“category”: “ENTERTAINMENT”, “headline”: “What You Missed About The Saddest Death In ‘Avengers: Infinity War’”, “authors”: “Bill Bradley”, “link”: “https://www.huffingtonpost.com/entry/saddest-death-avengers-infinity-war_us_5af9dc8de4b0200bcab7d3e0", “short_description”: “Directors Joe and Anthony Russo answer our most pressing questions.”, “date”: “2018–05–25”}The two fields we’re interested in are category and headline. Our task will be to determine the category based on the text of the headline. Note that each headline in this set has a single category. In some classification tasks, multiple categories are allowed.
The headlines in this set fall into 41 categories, and you can see that the data is reasonably unbalanced. The largest category (POLITICS) has 32,739 examples, while the smallest (EDUCATION) has 1004. To make this an easier task, we’ll only use data from the top 4 categories: POLITICS, WELLNESS, ENTERTAINMENT and TRAVEL. There are 76,511 examples in total across these 4 categories. I randomly shuffled the lines of data, and split the entire set into 3 files of length 10,000, 10,000 and 56,511 respectively. These are my test, dev and train splits.
Spacy cannot directly read data in this format, and so we have to convert to a binary format that Spacy can work with, using the DocBin structure:
from spacy.tokens import DocBin
import spacydef convert(infile, outfile):
nlp = spacy.blank("en")
db = DocBin()
with open(infile) as f:
lines = f.readlines() categories = ['POLITICS', 'WELLNESS', 'ENTERTAINMENT', 'TRAVEL'] for line in lines:
l = json.loads(line)
doc = nlp.make_doc(l["headline"])
doc.cats = {category: 0 for category in categories}
doc.cats[l["category"]] = 1
db.add(doc)
db.to_disk(outfile)
You can see in the conversion code that doc.cats has a value of 0 for all categories except the correct one, which gets a value of 1.
Name the test, dev and train splits astest.spacy, dev.spacy and train.spacy respectively, and you’re ready to begin training.
Step 2 — Model training
Now the data is prepared, we can get on with training a model. The first thing to do is use Spacy’s built in tools to create a config:
python -m spacy init config --pipeline textcat config.cfgPassing -- pipeline textcat to the tool tells Spacy that we’re training a single label text classifier, and so it creates the appropriate config containing all the parameters. You can edit it and make any changes to the config, but for now we’ll just stick with the default.
To kick off the model training, we use:
python -m spacy train config.cfg --paths.train ./train.spacy --paths.dev ./dev.spacy --output textcat_modelThe output as the model trains will look something like this:

The columns are E for epoch, # for number of training steps, LOSS for loss function on the training data, CATS_SCORE for the macro F1 score on the dev set, and SCORE which is the same but normalised score between 0 and 1. As training progresses, the training loss will decrease and the score should increase. Spacy handles shuffling of the training set between epochs. On my laptop, this model takes just a few minutes to train. Tasks with more data and more categories will take longer!
The config file contains parameters that tell Spacy when to stop training. The default is patience=1600, and max_steps=20000. That means training will stop if there’s been no increase in the score for 1600 training steps or the total number of training steps reaches 20,000. You can also set max_epochs, but by default that’s set to 0 and hence ignored.
When training has completed, both the best model and the last model will be written to the directory given by the --output flag.
Step 3 — Model evaluation
Now we can use Spacy’s built in evaluate command to evaluate the best model on the test split that we created above:
python -m spacy evaluate textcat_model/model-best/ --output metrics.json ./test.spacyThis command calculates the performance globally and for each individual category in terms of AOC (area under the ROC curve), precision (P), recall (R) and F1 score (F). As I randomly shuffled the data before splitting it into test, dev and train splits, results won’t be exactly the same but ought to be similar. This particular model gets a macro F1 score of 89.38:
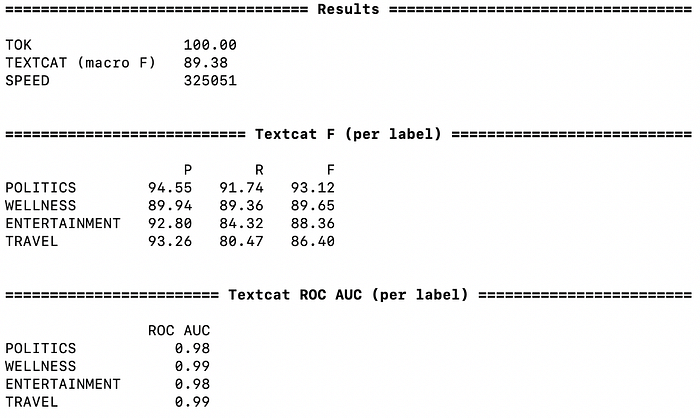
You can also check the metrics.json file for a more detailed version of the scores.
To try out the model on your own example headlines, you can import it in Python from the local directory:
import spacynlp = spacy.load(“textcat_model/model-best”)
doc=nlp("History is made: 10 new UK attractions for day trips and short breaks")
print(doc.cats)
For this headline, the output is:
{'POLITICS': 0.18584638833999634, 'WELLNESS': 0.25693294405937195, 'ENTERTAINMENT': 0.133481964468956, 'TRAVEL': 0.4237387180328369}The top category, with a score of 0.42, is TRAVEL — as you might expect!
Step 4 — Package for reuse
Finally, Spacy lets you package the model for reuse and installing using pip:
python -m spacy package textcat_model/model-best packages --name news_cat --version 0.0.0Conclusion
This post has shown how to build a text classifier using Spacy’s command line tools, evaluate it on test data, and try it out manually on new examples. Now you can try building models with your own data and your own categories.
I work with companies building AI technology. Get in touch to explore how we could work together.
