What’s a parameter in an LLM?
How to think about a billion parameters

The size of current large language models (LLMs) is being measured by the number of parameters. GPT-3 reportedly has 175 billion parameters. Phi-1.5 has just 1.3 billion parameters, while Llama has versions that range between 7 billion and 70 billion parameters.
But, what is a parameter?
LLMs are based on models called neural networks. But let’s ignore language models for now and focus on a simpler example. Suppose you’re an estate agent estimating the value of a house. You’ve seen lots of houses sold recently, and have come up with a simple rule of thumb that says the price of a house is roughly £75,000 for each room in the house. You can write this in a formula that says:

There’s one input— that’s the number of rooms. The other number — £50,000 — is a parameter. Perhaps next year, house prices will go up and you’ll update the parameter to £78,000. This formula gives you the flexibility to do that.
Your colleague has come up with a different rule. They believe that it’s not the number of rooms in the house that matters, but the number of bedrooms and the size of the garden. Their formula has two inputs and parameters:

Both of these formulas are models for estimating house prices. When the house down the road gets sold, you could compare your model’s prediction of house price with the price that it actually sold for. You could even have a competition with your colleague where you find a list of recently sold houses in the area and see which of the two models estimates house prices that are closest to the actual value they sold for.
Having discovered that neither model is very accurate, you could come up with a longer list of inputs that impact house prices, like how far away the nearest school is and the age of the house. By adding more and more inputs & parameters to your model, and adjusting the values of the parameters, your model might get better and better house price estimates.
Suppose that you and your colleague settle on 7 inputs that you believe are the most important to house prices. Rather than write the formula out, it can be drawn in a diagram:
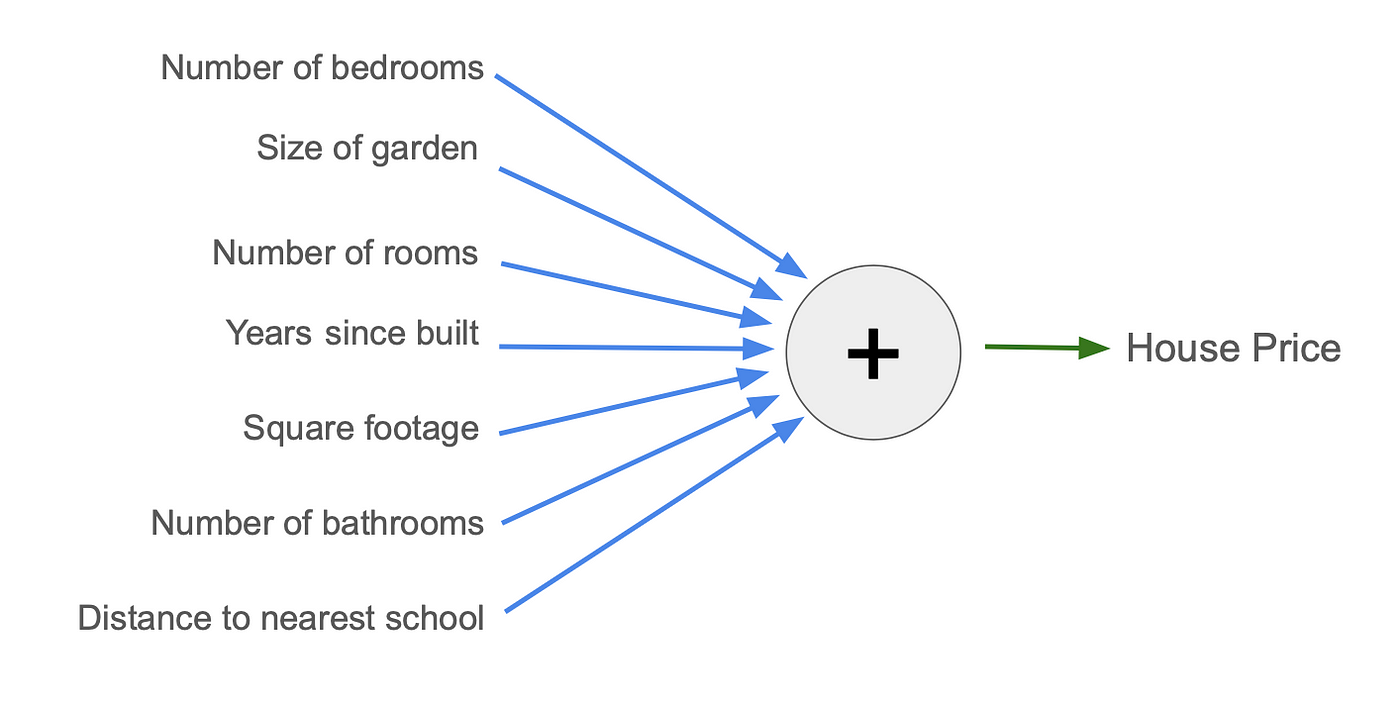
The inputs are on the left. Each blue arrow multiplies an input by a parameter, and then all are added together to give the estimated house price at the green arrow. In this diagram, there are 7 parameters, and those 7 parameters can be adjusted until you land on a good model.
So, a parameter is a number inside a model that we can adjust to make it more or less accurate. With 7 inputs we’d hope to make the model more accurate than with just 1 or 2. But we couldn’t create a model that took into account all the factors that affect house price and the random fluctuations that sometimes happen!
How does this apply to neural networks?
LLMs are neural network models. The building block of a neural network model is very similar to our current model for estimating house prices*. Neural networks are built by arranging many of these simple models into a grid arrangement — into layers that contain nodes:

This neural network model has 3 layers, with 7 inputs. The first layer has 2 nodes, the second layer has 5, and the last layer has 1. Each blue line is a parameter. As in the simple model, the inputs are the same and the output is still an estimate of house price. The difference is in how complicated the model is. There are a lot more steps inside this neural network to transform the inputs into the output. Because of this, we hope this more complicated model can give us better (but still not perfect!) estimates of house prices. As before, each of the parameters can be adjusted to make the model better.
How does this apply to large language models?
LLMs are large neural networks that are built up of many layers and many parameters. The key differences to our neural network example for house prices are:
- LLMs work with words as both inputs and outputs.
- The internal structure of the NN is different for LLMs from the example above— they use a mechanism called attention — though similar principles apply.
- LLMs have many layers and billions of parameters!
The key takeaway here is that parameters are the numbers inside a model that can be adjusted to make a model more or less accurate in its predictions. In very simple models, we can think about adjusting the parameters by hand. For neural networks and other complex models, the parameters are adjusted during a process called model training.
— — —
- For those who are sticklers for accuracy, the main difference is that our grey circle in a neural network becomes a more complicated function than just addition. But the details don’t matter for the purpose of understanding what a parameter is so I’ve left this part out for simplicity.
I work with companies building AI technology. Get in touch to explore how we could work together.
